Arabic Script Tutorial
Like all multi-lingual computing, Arabic computing is now firmly in the domain of Unicode. Unicode is an industrial protocol with the status of international agreement. It is designed to encode the elements of all known script systems in such a way that they become interchangeable between programs and operating systems. Its implementation is well underway.
Unicode eliminates the need to tamper with fonts to get special characters, but it is not a font. For legible text on screen and paper, Unicode depends on compatible fonts with the required characters, where necessary with additional dedicated font technology.
The Arabic Alphabet
The primary character inventory
Arabic alphabet is related to the Latin alphabet, as can be seen from its historical sorting order A/ALEF, B/BEH, C/JEEM, D/DAL:

Its modern sorting order is on the basis of similarity of the letters:

The modern morphological order can be broken down as follows:
- Historical initial letter ALEF

- Similar letters b t ṯ

- Similar letters ǧ ḥ ḫ
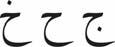
- Similar letters d ḏ r z
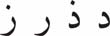
- Similar letters s š ṣ ḍ ṭ ẓ
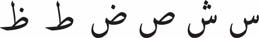
- Similar letters ʿ ġ f q

- Historical group k l m n
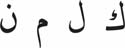
- Rest h w y
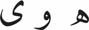
Derived primary characters
There is a number of letters, mostly skeleton-cum-mark combinations, that do not have independent status in orthography or sorting order:
- The hamza diacritic and its various supporting letters

- Morphophonologic use of YEH
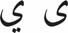
- Morphophonologic use of HEH
The secondary character inventory
Arabic spelling is not fully alphabetic: only short consonants and long vowels are written with the primary character set. For elaborate spelling or casual disambiguation, a set of secondary characters exists. They are written above or below a primary character, e.g.:
- U+064E FATHA to mark the vowel /a/

- U+064F DHAMMA to mark the vowel /u/

- U+0650 KASRA to mark the vowel /i/

- e.g.: kitābi

Traditionally, a repetition of the vowel marks is used at the end of a word to indicate that the indefinite article /-n/ is attached to the vowel:
- FATHA – FATHA to indicate /a-n/

- DHAMMA - DHAMMA to indicate /u-n/
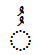
- KASRA - KASRA to indicate /i-n/

- e.g.: kitābi-n

Unicode deals with repeated vowel markers as if they are separate characters. This is a legacy from the metal typesetting era, when it was impossible to compose such minute superscript or subscript groups:
- FATHATAN to mark the vowel /a/ +n

- DHAMMATAN to mark the vowel /u/ +n

- KASRATAN to mark the vowel /i/+n

NOTA BENE: the ending –TAN, added to the original name, means “twice”.
Direction of writing
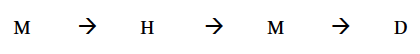
Arabic script runs from RIGHT to LEFT:
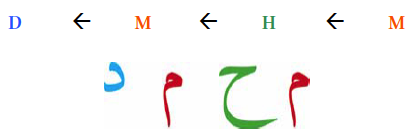
Letter group formation
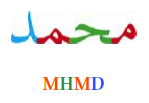
Efficient, streamlined connections assimilate letters into continuous groups to form words. Assimilation frequently takes the form of mergers. The merger of some letter groups can be so strong that letters lose their individual characteristics and instead contribute a distinctive feature to a kind of ideograph. In other words, the writing system becomes almost synthetic in nature, although it evolved from an analytic alphabetical structure:

(pronounced: muḥammad)
For technical and pedagogical reasons, there is a strong tendency to eliminate or simplify the connectivity of Arabic script; still even the simplest fonts maintain a minimal degree of connection between letters. This approach removes from Arabic script its synthetic, ideographic quality and turns it back into the analytic alphabet from which it evolved:
Conventional Analysis of Arabic Script
Most Arabic letters consist of a skeleton, e.g. a curve, and a marker:

Markers have a distinctly graphemic function. They combine with various skeletons to form other letters, e.g. the dot-above is used by eight Arabic letters:

In the conventional analysis, some skeletons have no independent meaning, e.g.: 
Other unmarked skeletons by themselves are already meaningful letters that differ from the ones characterized by a marker, e.g.:

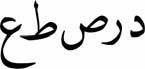

pro’s and con’s of the conventional analysis
Pro: Considering the combination skeleton and marker a single letter has advantage that:
- It meets the expectation of users.
- It conforms to conventional and legacy encoding.
Con: For scholarly work, the merger of skeleton and marker denies the evolutionary stages of the script, where the use of markers was casual, in a way similar to the use of vowels. Therefore, modern industrial encoding as inherited by Unicode has the disadvantage that:
- It misrepresents historical usage.
- It disrupts Internet searches by mismatching identical graphemes.
In manuscripts and even in older prints, markers are often incomplete or unreliable because markers were secondary, often redundant elements; or because markers were added later to interpret or eliminate ambiguities; because double markers sometimes co-exist to maintain original ambivalence.
Archigraphemes
A complete and unambiguous element of script is called a grapheme. Without markers, most skeletons become multi-interpretable, e.g. all these words share the same skeleton elements:
- transcription and meaning
- Shape
- ʿabdu “servant”

- ʿīd “feast”

- ʿinda “by, near” (preposition)

- ġayad “female tenderness”

In historical texts any one of them can look like this:
- Transliteration
- Shape
- EBD
(capitals are used to represent indeterminate graphemes) 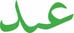
In this kind of spelling the skeletons are not “defective” graphemes, but valid archigraphemes. An archigrapheme is the common element(s) between two or more graphemes, minus the marker(s) that disambiguate them. The majority of historic texts are written with archigraphemes.
Unicode does not – yet – have the data structure to deal with archigraphemes and discrete markers as meaningful text elements.
Graphemes
A grapheme is the smallest unambiguous unit in a writing system. Ideally graphemes correspond to the plain text units of Unicode. In Arabic most of the accepted graphemes correspond with a phoneme (the smallest unambiguous sound unit in speech):
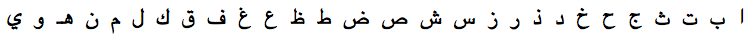
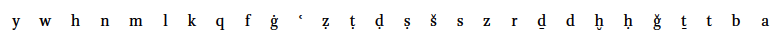
However, in a few cases this correspondence is not stable:
There can be more than one way to encode a single grapheme, e.g.:
The Arabic grapheme YEH WITH HAMZA ABOVE can have multiple encodings, which causes inconsistent usage:
- U+0626 YEH WITH HAMZA ABOVE

- U+0649 ALEF MAKSURA
U+0654 HAMZA ABOVE 
- U+06CC FARSI YEH
U+0654 HAMZA ABOVE 
More than one grapheme for a code, e.g.:
- U+06CC FARSI YEH
shares non-final dots with 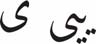
- U+064A YEH
shares final forms without dots with 
- U+0649 ALEF MAKSURA
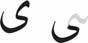
This inconsistency is not a feature of the Arabic writing system, but a consequence of the legacy approach adopted by Unicode. Accepting all graphemic markers as independent secondary characters with their own code points would make these cases unambiguous. The template for this solution already exists: in the latest version of the Unicode Standard, the combination of composition elements ALEF and HAMZA ABOVE has been declared canonically equivalent to the legacy pre-composed grapheme ALEF WITH HAMZA ABOVE:
U+0627 ARABIC LETTER ALEF
U+0654 ARABIC HAMZA ABOVE

U+0623 ARABIC LETTER
ALEF WITH HAMZA ABOVE
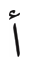
Allographs and Ligatures
Simplified support for graphic assimilation
In Arabic the abstract, nominal graphemes are represented by context-dependent allographs. Simplified support for Arabic handles contextual allographs according to two patterns, discontinuous and continuous assimilation:
| Pattern | final unconnected | final connected | Medial | initial |
| DISCONTINUOUS: 2 allographs |
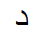 |
 |
|
|
| CONTINUOUS: 4 allographs |
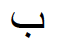 |
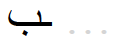 |
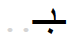  |
 |
full support for graphic assimilation
Graphic assimilation of Arabic letters is a sophisticated art – and the foundation of Islamic calligraphy – which produces well-designed and pleasantly legible script images. Without a thorough understanding it cannot be supported. E.g. in initial position, BEH coverage can get quite elaborate in naskh:



In metal-based typography and nostalgic computer fonts, only an inconsistent number of random ligatures remain of the original system:



Writing Arabic
Here are two additional aspects of Arabic script that have consequences for rendering systems:
Horizontal and vertical connections
The traditional connection is still reflected in a number of ligatures.
traditional assimilation

modified fusion

Unstable spelling caused by changing font technology
Spelling and font technology have mutually influenced each other since the fast emergence of computer technology for Arabic script. The fast development of font technology has the unintentional result that different fonts may require different spellings for the same printed image. For instance, most fonts cannot deal with al-lāhu, “God”:ALEF-FATHA
LAM-LAM-SHADDA-FATHA-HEH-DAMMA
correct data structure, wrong image

ALEF-FATHA
LAM-LAM-HEH-DAMMA
wrong data structure, wrong vowel image

For comparison, the correct image representing the above data structures:
complete vowels

incomplete vowels

A related phenomenon occurs when older font technology cannot handle the combination of ligatures and vowels, forcing the users into systematically misspelling words, e.g., the word al-islāmu “Islam”:
correct data structure, wrong image

wrong data structure, approximate image

For comparison, the correct image representing the above data structures:
complete vowels

incomplete and misplaced vowels

Rendering Arabic Script
Font technology
A font is an industrial product designed to enable handling Arabic with technology that is not designed for Arabic. In the design process, Arabic is an object that can be adapted at will: corners can be cut and rules can be broken. The resulting script can be seen as an “innovation”.

Script analysis and synthesis
The term script synthesis describes the effort to analyze and synthesize traditional calligraphic styles or high quality typesetting systems. In this approach Arabic is the subject whose integrity needs to be preserved when it is reproduced in digital form. Here the underlying technology is the innovation.

Note
Some of the most frequently seen typefaces only allow limited, unvowelled use:

Encoding Script for the Arabic Language
What to encode
Unicode uses a model resulting from earlier conferences about Middle Eastern computing: contextual shapes of one and the same letter are all attributed to a single nominal text code. This is the graphemic model:
| GRAPHEME | ALLOGRAPH | ALLOGRAPH | ALLOGRAPH | ALLOGRAPH |
| Character code | final unconnected | final connected | Medial | initial |
| U+062F | |
|
|
|
| U+0628 | |
|
|
|
There is single logical representation regardless the visual complexity of the assimilations, mergers or ligatures
Code page legacy
The original encoded Arabic character sets had external and internal limitations - external in the sense that only a small number of characters could be accommodated and internal in the sense that only simplified modern orthography for office use was supported.
Today there is no limitation to the number of characters that can be handled simultaneously by a computer system, while the original purely synchronic, limited scope has changed into a diachronic and comprehensive ambition. Unicode is being extended with additional characters to handle literary orthography, archaic orthography, as well as contemporary Qur’anic orthography.
Historical Qur’anic orthography is fully archigraphemic and therefore not supported by Unicode graphemic model. This serious defect is curiously matched in Arabic studies by the absence of an authoritative critical text edition documenting the transmission through the ages of this key historic text.
Encoding Arabic Script for Other Languages
Extra characters
The Arabic character set has been expanded over time to cover speech sounds not used in the Arabic language. Practically always the existing archigrapheme-cum-marker template is used, e.g.:
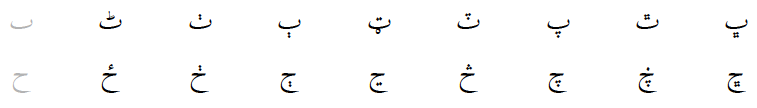
Regional calligraphic and typographic preferences
Various user communities of the Arabic script have specific calligraphic traditions that result in preferences for certain fonts or script styles. For instance, the preferred way to write Urdu is a subtle Persian simplification of Arabic called nastaliq script1:

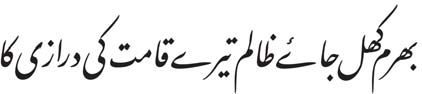
The same text in alien simplified naskh would not be acceptable:
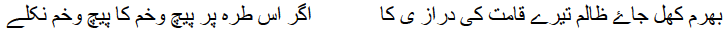
Calligraphic preferences sometimes cause incompatible encoding
There are instances where one and the same Arabic letter received a different encoding because a regional calligraphic style shaped it differently than the ubiquitous naskh. A case in point is the Arabic letter KAF, which in nastaliq has an extra swash in the final forms. Unicode now has an extra code U+06A9 KEHEH, causing identical letters to be encoded with language dependent codes. As a result, two out of the three letters of the place name MECCA are not interchangeable between various Arabic-scripted languages:
| mīm | kāf | hāʾ | |
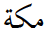 |
U+0645 MEEM | U+0643 KAF | U+0629 TEH MARBUTA |
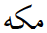 |
U+0645 MEEM | U+06A9 KEHEH | U+0647 HEH |
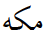 |
U+0645 MEEM | U+06A9 KEHEH | U+06D5 AE |
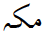 |
U+0645 MEEM | U+06A9 KEHEH | U+06C1 HEH GOAL |
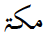 |
U+0645 MEEM | U+06A9 KEHEH | U+06C3 TEH MARBUTA GOAL |
(the GOAL variants of HEH and TEH MARBUTAH are also calligraphy-based mismatches)
Basic Lay-Out
There exist three distinct line-breaking patterns in Arabic-scripted languages:
Graphic: equidistant and equivalent spaces follow final forms and discontinuous letters2:
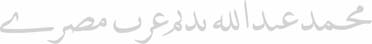
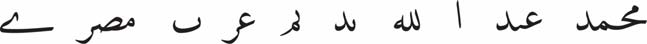
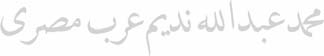

Orthographic: in addition to word-separating spaces and final forms, hyphenation is used for line-breaking, just like in Latin-based orthographies:


a: Historic Arabic
early archigraphemic Arabic

b: Arabic, Persian, Urdu, etc.
semi-alphabetic modern Arabic

c: Modern, non-Arabic
fully alphabetic Uyghur Turkic

NOTA BENE: so far only pattern b is documented and supported by Unicode.
Thomas Milo, 2005-2012 | www.decotype.com
The languages section of this article has been edited. To view, please visit: Arabic Script Tutorial by Thomas Milo.
1 bharam khul ǧāʾē ẓālim tērē qāmat kī darāzi kā - agar us tura ē pur pēč ū ḫam kā pēč u ḫam niklē“O tyrant, the mistake about the tallness of your figure will be rectified - if the curls and twists of your hair full of curls and twists are straightened out” (Ġālib, quoted in Finn Thiesen, A manual of Classical Persian Prosody with chapters on Urdu, Karakhanidic and Ottoman prosody, Wiesbaden 1982, p.188)
2
The sample (repeated in the text columns) illustrates the spelling evolution in Arabic, as well as the
complete phonologic, lexical and orthographic integration of Arabic words in Uyghur (spoken in China):
Arabic: muḥammad ʿabdu l-lāh nadīm ʿarab miṣrī;
Turkic: muhämmäd abdullah nadim äräb mısırlıq
(Mohammed, Abdallah, Nadeem [personal names], and “Arab”, “Egyptian" – from Arabic miṣr, “Egypt”)